An Introduction to Natural Language Processing: Data Analysis Like Never Before
Ever found yourself frustrated with a chatbot’s inability to comprehend your messages? Ever wondered about the underlying cause? Well, the answer is quite straightforward—it boils down to the absence or deficiency of Natural Language Processing, commonly referred to as NLP. So, what exactly is Natural Language Processing? Why is it essential, and where does it […]
Ever found yourself frustrated with a chatbot’s inability to comprehend your messages? Ever wondered about the underlying cause? Well, the answer is quite straightforward—it boils down to the absence or deficiency of Natural Language Processing, commonly referred to as NLP.
So, what exactly is Natural Language Processing? Why is it essential, and where does it find application?
Let’s break down NLP in simple terms and elucidate the entire process through a natural language processing tutorial. Every expression, whether written or spoken, contains information. This information encompasses words, tone, and topics, representing a form of data from which value can be extracted. This wealth of information provides insights into human behavior, enabling us to understand others.
However, a challenge arises due to the overwhelming volume of information, making it impractical for humans to track everything. Let’s clarify this.
An individual can generate a multitude of sentences and declarative statements, each laden with its complexities. Manually managing and analyzing this data is beyond human capacity, given the sheer number of declarations.
This data, collected from conversations, declarations, social media activities, etc., is unstructured and challenging to fit into relational databases representing the world. The result is a labyrinth of information that is intricate and cumbersome to comprehend. Enter the game-changing solution—Natural Language Processing.
This revolutionary technology alleviates the burden on humans to manually interpret speech or text data. Cognitive methods have streamlined the process, making it easier to discern the meaning of data and detect speech patterns.
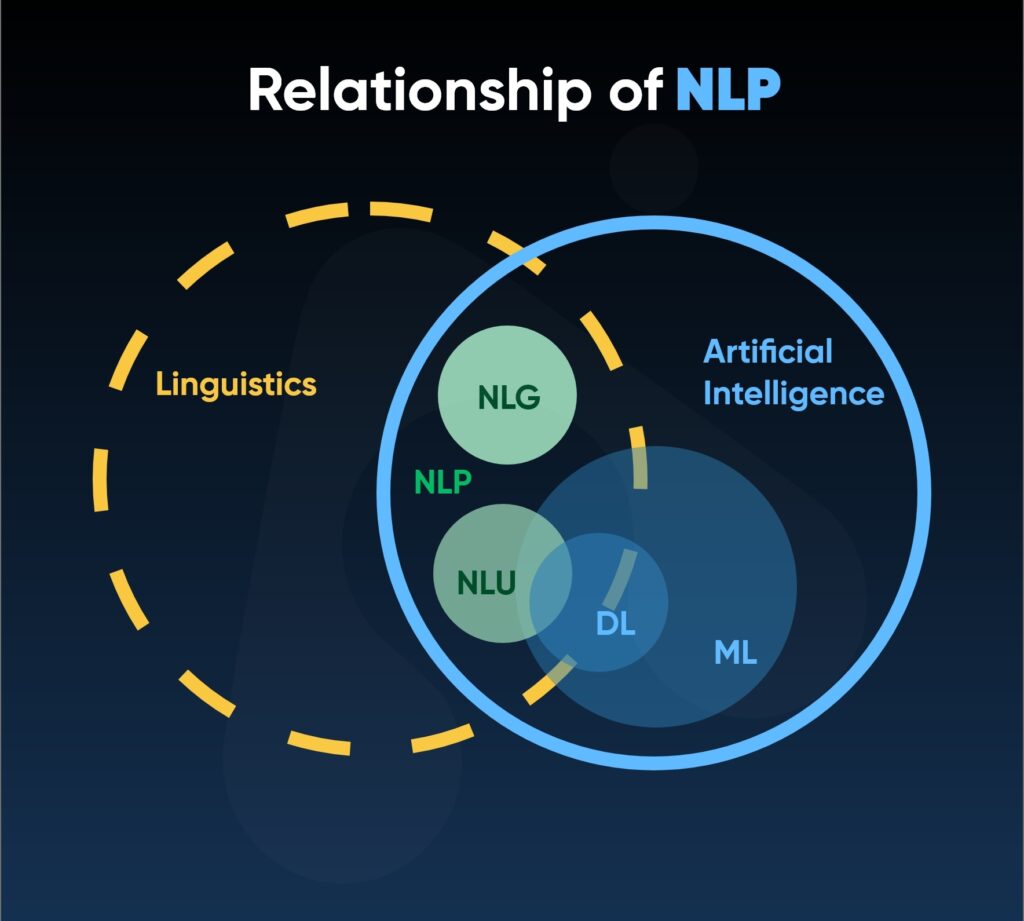
Crucially, the efficacy of NLP hinges on Artificial Intelligence, Machine Learning, and Deep Learning, which collectively facilitate the entire NLP process. In essence, NLP has evolved into a comprehensive natural language processing solution, sparing individuals the manual efforts and ushering in a new era of understanding and interpreting vast datasets.
This is just an introduction to natural language processing, there is so much more that we must be aware of. Now, let us understand it in a technical way in the natural language processing tutorial.
What is Natural Language Processing?
NLP is a sub-category of artificial intelligence, information engineering, computer science, and linguistics that helps machines understand human language. It helps in analyzing the data that humans refrain from doing but can be of great potential.
In simple terms, NLP helps to understand plenty of data and analyze it to make it easy for computers to communicate with humans using NLP machine learning, deep learning, and AI technologies.
Let us give you a brief about the history of NLP. In the 1950s, the first theory about NLP came up in the article “Computing Machinery and Intelligence” by Alan Turing which showcases the criterion of intelligence around the Turing test.
However, in 1954, the automatic translation was done as a Georgetown experiment that translated sentences from Russian to English. With this, NLP gained popularity, and slowly new researches were added to it including statistical machine transactions in the 1980s, and so on.
In the present time, NLP is growing at a rapid rate with the increase in computation power and enhancement in data access. This allows practitioners to achieve desirable results in sectors including human resources, finance, media, healthcare, and so on.
Why is NLP important?
We are living in a time where companies’ motive is to improve the user experience at every step. They are not leaving a single stone unturned to evolve the experience of customers ensuring to be a step ahead of their competitors.
Brands are well-advanced to work around AI-assistant channels, computational linguistics, retrieving data from websites or documents, and so on. Customers and businesses are now embracing NLP and cloud computing to be more accurate, automate services, search through FAQs, and even have conversations with customers using Chatbot.
Customers can have instant answers to their queries whereas companies can focus on higher-value data without manual help. The agent side for the companies is easily covered with NLP that work as virtual assistants (mostly) that use the data to interact efficiently with users.
The data analysis with NLP has a lot of potential to grow that was earlier hidden in the text troves that use NLP machine learning algorithms for analysis. With a brief explanation of the working, let us get to the pros and cons of NLP as per its approaches – machine learning and grammar engineering (we will briefly talk about them later in the blog).
With this said, let us dive into the deep of the NLP world with its working and other major aspects that one must be aware of.
How does Natural Language Processing Work?
Natural Processing Language or NLP rules must be known to the machines to work including phonology, semantics, syntax, morphology, and pragmatics, above all – ambiguity. But before that, let us understand what workflow looks like.
Standard NLP Workflow
NLP works on the major workflow model which is a step-by-step process to reach the desired output. The whole process is described in the below image in the form of text wrangling, pre-processing, parsing, and outcome. These are explained below in the working and techniques section in detail.
With this said, let’s start with its basic working in which the above terms will be cleared more practically.
Words in a Sentence
The nature of words is the first and foremost thing that must be covered including adjectives and noun phrases. The verb, tense, infinitive form, number, person, etc. are all parts of PoS (Part of Speech tagging) that are later converted into the document with the help of natural language processing and text mining.
For instance, in a sentence, all the necessary information is explained in the part of speech, inflected forms, verbs, nouns, and so on that are used to compute an output. This is about the simple sentences that even humans and predict but what about the sentences that are a bit complex?
To solve them, NLP uses two major approaches: statistical and symbolic. In the statistical approach, the learning phenomena are learned by the machine using the natural language processing algorithms through which analysis is done perfectly. In the symbolic approach, there are several rules, written that are learned automatically by the model.
This falls under Rule-based PoS Tagger or Brill Tagger which helps in getting to the correct output. The PoS tagging used in statistical approaches is considered a sequence labeling problem. In this, the sequence of words is divided into the respective tags that are then used to decide the next word.
For instance, if the sentence “Max is planning” is already available then PoS tags are used to come up with the next sentence that will make sense. However, these don’t work on their own but rather depend upon Conditional Random Fields (CRF) and Hidden Markov Models (HMM). that are trained using the data with the PoS tag words.
Words to Sentence
We have seen that NLP can easily work around the words and understand the instances. But what about the syntax? Where is NLP going to use it? It can be a bit tricky to understand syntax. The words are grouped together but in a relatable format in the chunk units.
The NLP uses Parsing for it to analyze the sentences as per the grammar of the NLP. The tree is built to understand the context of the sentence as per the grammar. This is known as the parser tree that annotates the actual meaning of the NLP.
Meaning of Words
The meaning behind the words can be extremely confusing sometimes. The use of word “times” can be used in two contexts that are easy to understand in English but for a computer, it can be confusing.
This leads to two major concerns that NLP faces
Synonymy – Words with similar meanings
Polysemy – Words with several meanings
Hypernymy, hyponymy, and antonymy are different types of semantic relations that are also used. Compositional semantics helps to combine the words to form a meaning whereas lexical semantics help in putting the meaning to words.
In addition to this, WSD – Word Sense Disambiguation is used in the sentence to identify the polysemic sense of words.
For instance,
He made the world record.
We have a record of the conversation.
The syntax and PoS tagging are similar in the above sentences which might make it difficult for the NLP to understand it. In this type of phrase, a deep approach is followed that uses world knowledge. The knowledge helps in removing ambiguity and placing the right meaning to the words.
Pragmatics
The context of the sentence is the next thing that is essential to extract the actual meaning. Is it a joke? Sarcastic comment? Serious comment? These things hold a lot of importance when it comes to analyzing the data.
For instance,
Will – That was a dumb move.
James – Well, thank you, that’s so sweet of you.
Why dumb is related to sweet? What was it – sarcasm, joke, or plain irony? These fall under the complex mechanism of the NLP that works on the intent of the words. A classifier can be trained to determine what the tweet or status is all about.
It can include word frequency or even adjectives such as exaggeration or unexpectedness that are added. However, there is always room for improvement and with time the NLP system can adopt the intentions as well.
Syntax & Structure
When it comes to programming languages, then you need to know that syntax and structuring always go hand in hand. In NLP this includes conventions, rules, principles of the words, phrases, clauses, and so on.
These come hand in several ways including parsing, annotation, and text processing. However, to grasp it you need to know that it holds a lot of value with the major text syntax or more of the grammar in the NLP.
POS (Parts of Speech) Tagging – The POS is the word category that showcases its role and helps the NLP work. It includes categories like nouns, verbs, adjectives, and adverbs.
Constituency Parsing – In this, the grammar is used to check the sentence and analyze it hierarchically.
Chunking or Shallow Parsing – in this, the phrases are used to depict the meaning. This is divided into major five categories Verb Phrase (VP), Noun Phrase (NP), Adverb Phrase (ADVP), Adjective Phrase (ADJP), and Prepositional Phrase (PP) (as used above in the parsing table).
Dependency Parsing – In this, the grammar dependency is analyzed in the sentence to understand the relationship between the tokens.
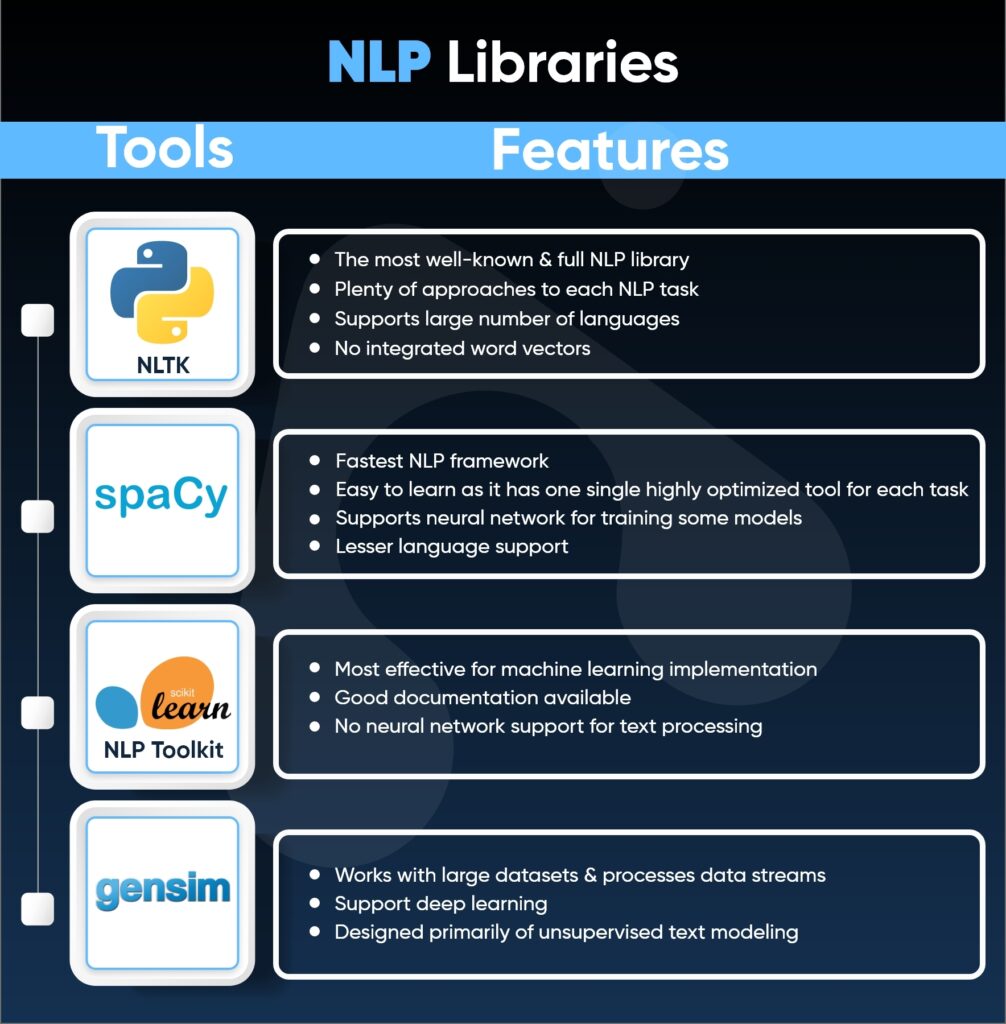
However, the natural language processing toolkit and libraries are left which are also the major part of the NLP programming language. The NLP works on the different processing libraries such as:
Out of these libraries, the NLTK is the most famous one that is widely used by developers. The NLTK is written in Python offers great support for its community and is also a simple language that is easy to learn.
These are the major parts that are added as per the system to analyze the data. The segmented text into word processing is required that be worked up in the form of tokenization. Then some questions and answers perform semantic, syntactic, and morphological analyses.
What are the major Natural Language Processing (NLP) Techniques?
Even with so much information in our hands, some non-NLP developers are not very aware of it. The whole process of manipulating and understanding complex data can be extremely difficult to manage otherwise.
R and Python-like NLP programming languages are used to write the code lines but let us summarize the whole NLP vocabulary to you before diving into it. So, let us dive into the natural language processing (NLP) techniques to have a better understanding of the whole concept or you can say natural language processing tutorial for beginners.
Bags of Words
We have mentioned the type of grammar and its working above so it will be easy to grasp the bags of words that work as the words in a piece of sentences or text. The occurrence matrix is created for the document and sentence that then places the word or grammar in proper order.
The occurrences and frequencies are then compiled together in the form of a classifier that is trained for the analysis. However, every aspect has good and bad including the absence of semantic context and meaning using NLP techniques in AI.
What about the stop words (a and the)? The noise analysis? To work on these common issues (TFIDF) – The term Frequency – Inverse Document Frequency is used. This works with algorithms to consider the text and improve the bag of words.
Tokenization
The sentences and words are segmented together in the tokenization process. In this, the sentence is cut into different segments known as tokens and is further divided into the characters including text and punctuation as shown below.
The language of English and NLP work differently so to make it easy for the machine to understand its tokens are formed. The segmented languages give the meaning of each block helping the machine to place the actual meaning to words.
To avoid complications, Tokenization can eliminate punctuation marks if necessary. Otherwise, a separate token is assigned to punctuation.
Stop Word Removal
The stop words as mentioned above are the prepositions, pronouns, and articles in the English language. The fact is that stop words are extremely common in a sentence but hold no importance for natural language processing algorithms. As a result, the objects are filtered out, and frequent terms are eliminated that hold no information around the text.
The pre-defined list of keywords is used to remove the stop works that free up space in the database as well. However, stop words don’t have a universal list. They are built or pre-selected as per the requirements of the software.
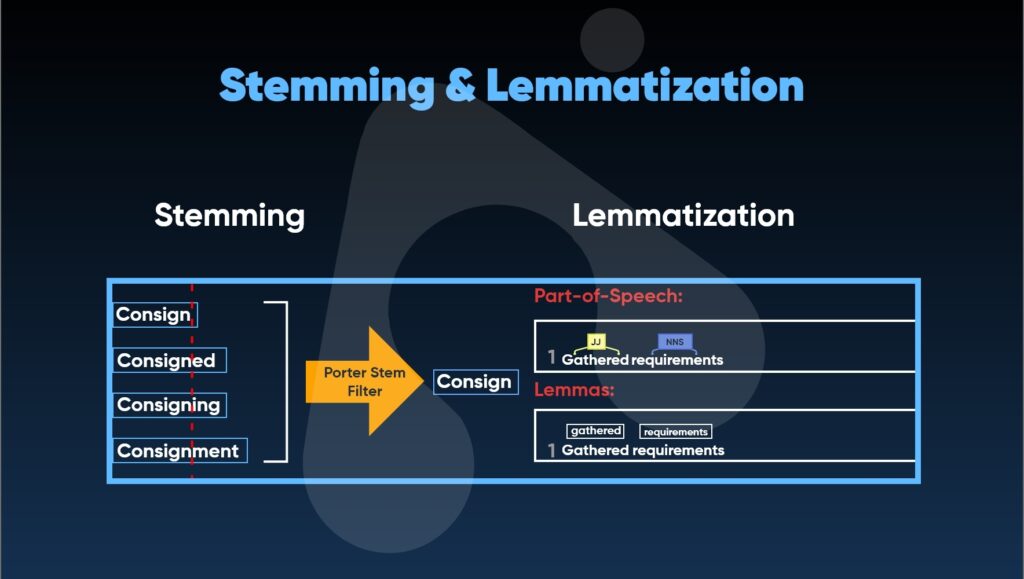
Stemming & Lemmatization
This is another aspect of the NLP that one must be aware of. The addition of the word to the root is mainly termed as stemming. In common words, adding prefixes and suffixes at the beginning or end of the word is commonly referred to as stemming.
However, there are common issues stemming from expanding or creating a new word that is called inflectional affixes and derivational affixes respectively. Due to this NLP programming languages such as R and Python are used with different libraries to ensure that the stemming process is performed easily.
Whereas in Lemmatization, the form of a word is reduced or the same words are grouped. For instance, the tenses, synonyms, etc are grouped according to their meaning in the standardizing words.
The dictionary form of the words is used in the lemmatization in the form of the lemma in which the natural language processing algorithms scan the dictionary and link the words together. This is explained a bit in the image given below.
Topic Modeling
In this, the hidden structure in the documents and text is uncovered as per the processing of individual words, and contents, and then assigning value to them. However, the assumption is the major part of this technique in which topics are mixed as per the words.
Once the distribution is done the hidden text is discovered using natural language processing algorithms to find the real meaning of the text. Around two decades back, Latent Dirichlet Allocation (LDA) was launched as the topic modeling technique that works on the unsupervised learning method.
In this, the learning process depends upon one output variable, and algorithms are used to analyze the data and find the pattern. LDA uses the related words group as:
It uses random topics and assigns the numbers to them that you wish to discover. These random topics are defined as numbers that are mapped out using an algorithm to find the words in the documents.
Every word is scanned by the natural language processing algorithm considering the probability and reassigning the words to the topic. Multiple scans are done and probabilities are calculated until the algorithms reach the outcome.
LDA works on the mixture of topics in the document that is opposite to the K-means algorithm (that works on the disjointed topics in a cluttered form). This makes the results more realistic and explains the topic in a better way. With this, you can say that it is the right time to invest in AI application development.
Word Embeddings
It is one of the essential natural language processing (NLP) techniques in which the vector form is used to describe the real numbers in the NLP. The natural language is not easily processed by the computer. So to overcome this, the vector forms are used to describe the numbers.
This captures the essence of the words and showcases the relationship of a real number to the NLP. The vector length of 100 is used to represent the fixed dimension.
Named Entity Disambiguation & Named Entity Recognition
In the disambiguation, the entities are identified in a sentence such as the name of the famous person, brand, etc. For instance, the news states the new product launched by Apple. The named entity disambiguation is used to infer that Apple is the brand here and not fruit with the help of NLP techniques in AI.
Whereas in the named entity recognition, the entity is identified and categorized according to the date, organization, person, time, location, and so on.
For instance, “On 5th October 2019, Apple launched the latest version of the iPhone in Australia.” (the news is not true)
Here, the Named Entity Recognition will dive into the sentence in the category:
Apple ORG
5th DATE
October DATE
2019 DATE
Australia GPE
***ORG – Organization & GPE – Location***
Language Identification & Text Summarization
In language identification, the language is identified as per the content using syntactical and statistical properties. , text summarization is similar to language identification, but it shortens up the text that is identified making it a vital part of a natural language processing tutorial for beginners.
Use Cases of Natural Processing Language
NLP works amazingly well when it comes to speech processing, natural language processing, and text mining of the data. The concept is extremely fascinating showcasing the real value and working in several fields. If we talk daily, then NLP is used in several industries such as:
Disease Prediction – With the help of the electronic health record of the patient, the NLP can easily predict and recognize the symptoms of diseases. Be it schizophrenia, depression, or cardiovascular disease, NLP can comprehend the actual status of the patient using the health record and treatments.
Cognitive Assistant – It is a personalized search engine that works as an assistant searching a song, reminding you of the name in case you forget it, and so on. This uses NLP and analyzes the user data to give the output.
Sentiment Analysis – This helps the companies to understand the requirements of users. The user data sets are used to extract information and identify what they expect from the service. It includes decision drivers and customer choices that help the users to offer top-notch services.
Fake News – NLP can identify the news and find out whether the source is reliable or not. It helps in understanding whether the source can be trusted or not
Identifying spam – There is a filter that is used by Google and Yahoo that helps in filtering the emails to check whether it is spam or not.
These are just a few of the uses of NLP that are working amazingly well and offering top-notch solutions to the organization. It is used as voice-driven interfaces, finance reports, comments, news, talent recruitment, and even litigation tasks.
Challenges faced by NLP
Just like other platforms, NLP has its own sets of challenges that are explained below:
Natural Language Understanding
NLP widely depends upon the NLP or Natural Language Understanding that helps in the generation of natural language processing and text mining. However, real understanding can be a bit daunting for the developers including the structure and innate biases.
Then there is reinforcement learning which means that the model will learn everything on its own including predictions, features, and algorithms. However, not everyone supports this approach and believes that they should explain the process to the model.
The machines are also not capable enough to understand human emotions and they need to know about them. This makes the prediction and analysis of data easy to understand and use for leverage.
NLP for Low-Resource Scenarios
What about the dialects and low-resource language? This universal problem is yet to have a solution to solve the issue of training data. The natural focus can be easily worked up with specific languages. The universal language model, cross-lingual representation, and its impact are the major factors that are yet to be discovered.
Reasoning about Large or Multiple Documents
The neural network is used in the current model but they are not that stable with longer context. The multiple documents and large data sets make it difficult to analyze the content easily which requires scaling up dramatically.
Solutions of Natural Language Processing
natural language processing and text mining are used by several companies already around the world and is categorized as artificial intelligence sub-sections. The trends are slowly adopted by many others to automate crucial processes.
Let us walk you through some of the top solutions that are ruling the market.
Digital Genius
This solution is mainly to enhance customer support. It works on repetitive processes and automates them easily to understand the customers. Deep learning and APIs help in understanding the requirements of the clients and customers with other innovative technologies.
AnswerRocket
With this tool, it is possible to easily get the reports of the subject without waiting for a longer period. It is developed using reasoning and logic, to sum up the solution that can help in getting the answer in just a few seconds. The tool explores data and helps in analyzing the result easily.
Netomi
This is a far-fetched dream that is now true for the users. The tool is capable enough to automate the resolutions and help the customers easily. The employees can easily multiply the workforce and understand the requirements of the customers with the help of classification models.
IBM Watson
The IBM-based solution is based on NLP machine learning development and NLP techniques in AI that help the employees understand the bots, platforms, and applications making the interaction between computers and humans easy.
Semantic Machines
This solution is a bit different in that focuses on technology and transfers the data easily to help the machine to understand it. In addition to this, it works as the conversational AI that is going to rule the market in the coming years. The tool is used for dialogue processing and NLP to support tasks like deep learning, speech synthesis, and linguistic domains.
Future of NLP
If we talk about the present time, NLP is becoming an integral part of the technology, especially with machine learning, deep learning, and artificial intelligence solutions as its core factor. By learning from them, the companies are now able to interact with the customers easily and make a difference in the market.
Natural language processing (NLP) techniques are majorly used by companies to enhance their customer interactions, and interaction with data, and reach the desired outcome. The processes are becoming better and faster with the help of natural language processing (NLP) techniques.
This is bringing in a new phase of communication with the machines, companies are now easily making decisions and becoming more flexible. It is a paradigm shift in technology in the market while maintaining customer sentiments in mind.
Organizations are going to become smarter with the NLP and mainstreaming the intelligence in a manner that can be beneficial for them. The integration of the NLP with other technologies is going to change the way users work with machines including computers and smartphones.
When it comes to the NLP then the sky’s the limit and the future is going to shine brighter with advancements.
With this said, if you have any queries about the NLP then drop a comment below, or if you want to develop the app using this technology then feel free to contact us.
Consult our experts
Elevate your journey and empower your choices with our insightful guidance.
Omji Mehrotra
VP - Delivery at Appventurez
Expert in the Communications and Enterprise Software Development domain, Omji Mehrotra co-founded Appventurez and took the role of VP of Delivery. He specializes in React Native mobile app development and has worked on end-to-end development platforms for various industry sectors.

 This is just an introduction to natural language processing, there is so much more that we must be aware of. Now, let us understand it in a technical way in the natural language processing tutorial.
This is just an introduction to natural language processing, there is so much more that we must be aware of. Now, let us understand it in a technical way in the natural language processing tutorial.